In this example the treatment table has two columns:
t_0: one continuous dose
t_0_bin: one categorical regime label
So the estimand is
\[
\mu(t, c) = \mathbb{E}_P[Y^*(t, c)]
\]
The output is one average response per requested row of a treatment grid. Here we will visualize that surface as one dose-response line per categorical level.
Tip
Think in terms of a treatment table, not a special-case estimator API:
fit(X, t, y) takes covariates X, a multi-column treatment table t, and outcomes y
grid is another treatment table with the same columns and compatible dtypes
predict(t=grid) returns one estimated average response per row in grid
This page compares four estimators that accept the same mixed treatment table:
Estimator
Role in this tutorial
DirectNoCovariates
Observational baseline: regress Y on the treatment table only
DirectRegressor
Outcome regression: model E[Y | X, T] and average over X
GPS
Score-adjustment method: add a stabilized treatment score to the outcome model features
DoublyRobustPseudoOutcome
Outcome regression plus score correction, followed by a final smoother over treatment
Note
All causal interpretations below assume consistency, no unmeasured confounding after conditioning on X, and overlap across the treatment combinations you want to evaluate.
The table has five observed covariates, one continuous treatment column, one categorical treatment column, and one outcome column.
NoteOptional: How this synthetic dataset is constructed
Synthetic2MultidimDataset starts from the confounded continuous-treatment benchmark SyntheticDataset2, then adds a categorical treatment coordinate by binning the continuous treatment into n_categorical_treatments levels.
The parameter mutual_info=0.7 weakens the link between the two treatment coordinates without removing it completely, and categorical_effect_scale=0.2 makes the categorical coordinate change the response surface directly.
This gives a benchmark where:
the continuous dose matters
the categorical label matters
treatment assignment is still confounded through X
Important
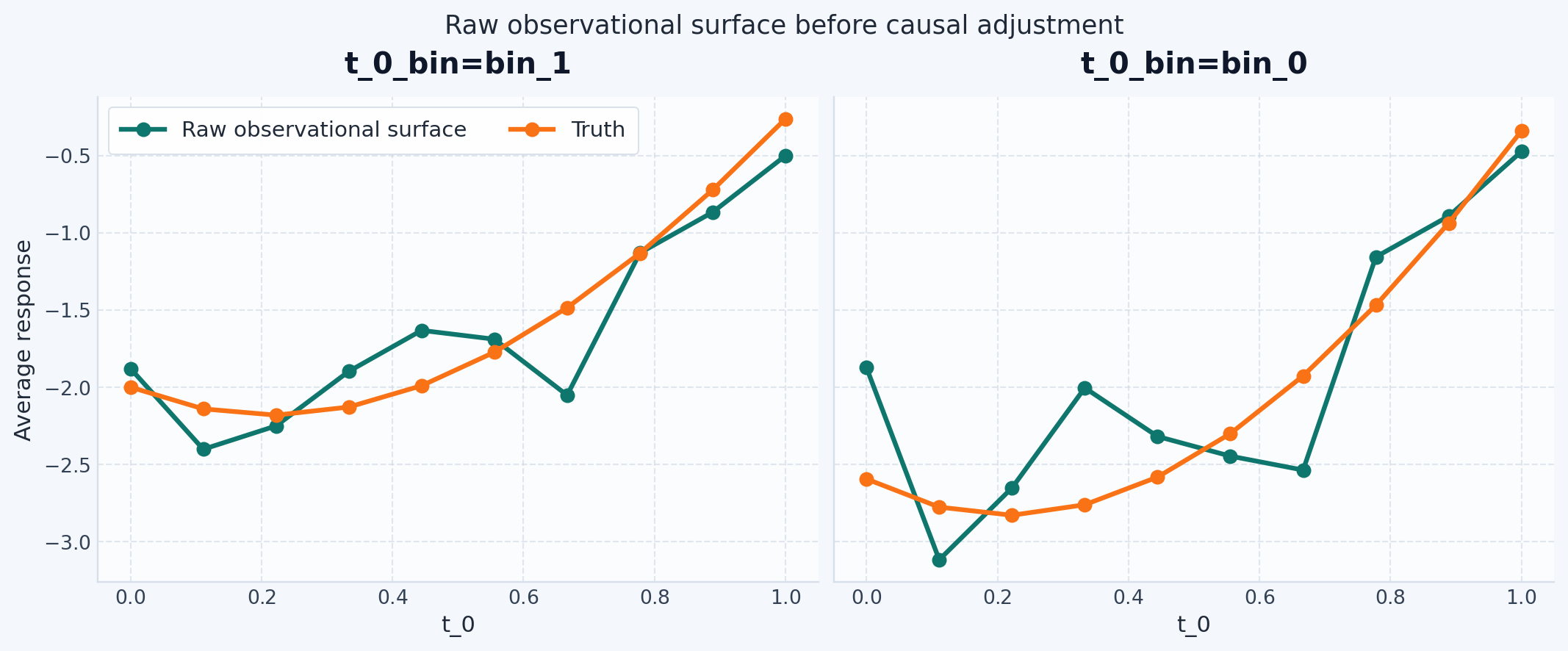
DirectNoCovariates accepts the mixed treatment table, but it does not adjust for confounding. In this dataset, any method that ignores X is still observational.
Step 3: Define practical model builders
The nuisance models below use the same expressive forest defaults. The only deliberate exception is the final doubly robust smoother, which uses a spline basis over the continuous treatment coordinate and a linear regressor over the expanded treatment features.
make_cartesian_treatment_grid replaces each continuous treatment column with evenly spaced points, keeps the observed categorical levels, and returns the Cartesian product. In this example that means 10 dose values times 2 categorical levels.
Note
The prediction contract is unchanged from the single-treatment guides: pass a treatment table to predict, and get back one average response per row of that table.
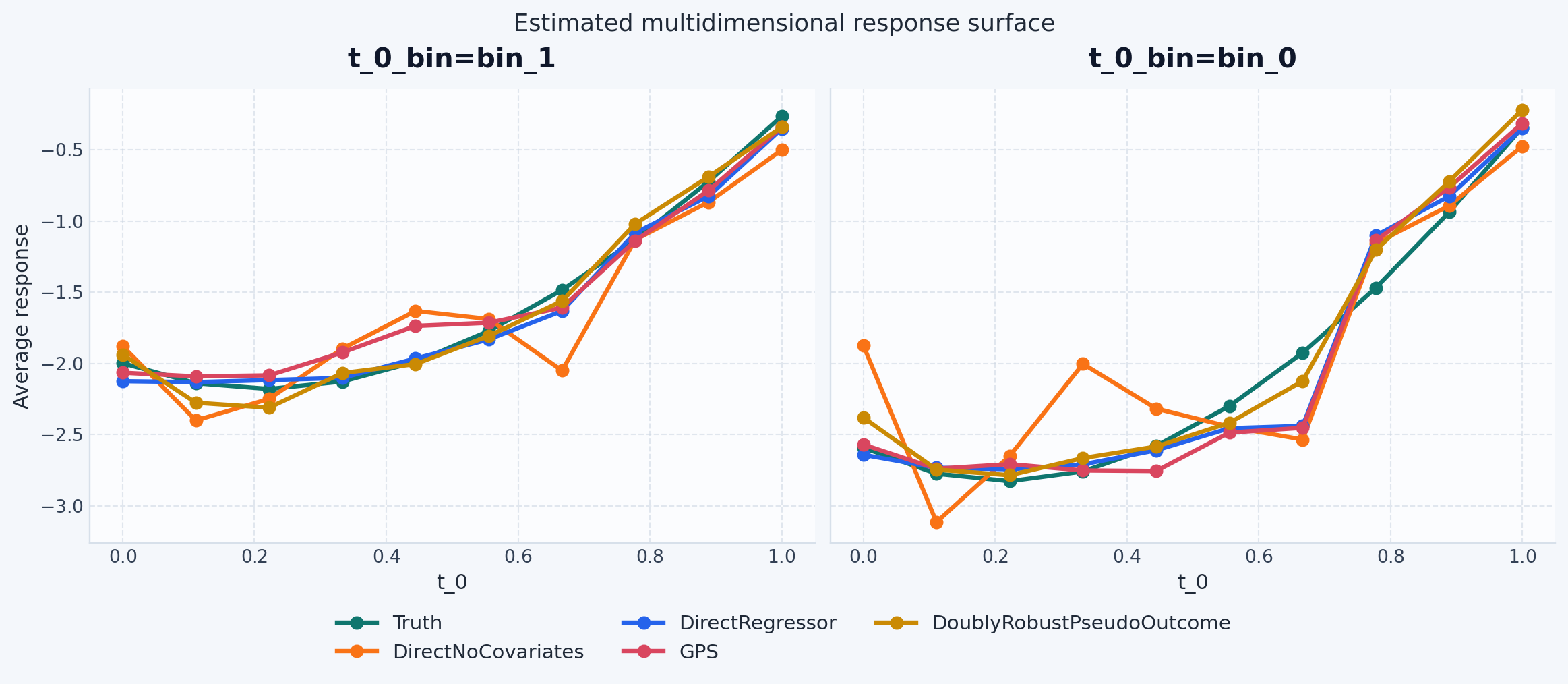
Because this is a synthetic dataset, we can evaluate the true average potential outcome surface exactly for every row in grid. That makes the rest of the tutorial a benchmarking exercise, not just an API example.
DirectNoCovariates is a useful observational baseline, but it is not a causal estimate. The model ignores X, so even after splitting by t_0_bin, the continuous dose remains confounded by the covariates.
Step 7: Fit DirectRegressor
DirectRegressor uses the same mixed-treatment outcome model, but now the model sees both X and the treatment table. Prediction averages over the observed covariate sample at each requested treatment row.
direct = DirectRegressor( outcome_regressor=make_forest_mixed_treatment_regressor(categorical_col))direct.fit(X, t, y)direct_curve = direct.predict(t=grid).flatten()
Step 8: Fit GPS
GPS augments the outcome model with a treatment score computed from predict_density(X, t). In this example that score comes from PermutationWeighting, which returns a stabilized density-ratio-style quantity. So this is best read as a score-adjustment example, not as a parametric conditional-density example.
DoublyRobustPseudoOutcome uses the same forest outcome model and the same stabilized score model, then smooths the pseudo-outcomes over treatment with a spline basis over the continuous coordinate and encoded indicators for the categorical coordinate.
Treat the MAE table as a compact summary, not the whole story. The faceted plot is still the best place to see whether an estimator misses one categorical level or only part of the dose range.
Note
With shared forest nuisance models in place, the remaining differences are more about estimator structure and stochastic variation than about an obviously underpowered outcome or score model. The doubly robust estimator still uses a different final smoother by design.
Optional: Verify discovered support with lookup
The main tutorial above uses four estimators because those are the current average-response estimators tagged as supporting both multidimensional treatments and mixed continuous/categorical treatment types.